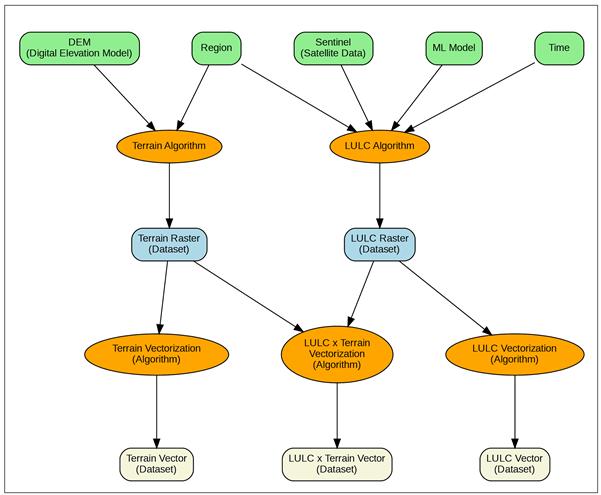
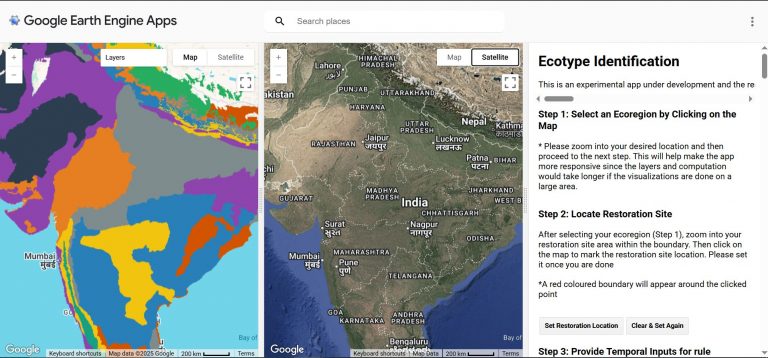
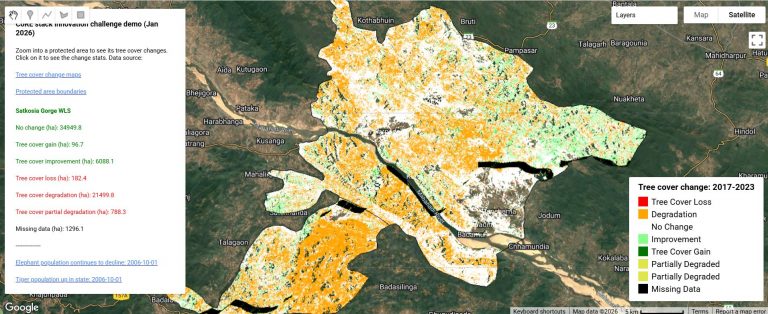
Feb 23, 2026: Three contributions have advanced to the next stage of follow-on support to enhance the PoCs into a full stack integration!
Rolling dev calls: We will keep updating this table with weekly developer community call recordings and relevant posts. Suggested order to view these is Session 05, and then the others.
| Session 01 | Nov 28, 2025 | Introduction to CoRE stack datasets, data organization, API invocation. Understand the data structure. | Video |
| Session 02 | Dec 5, 2025 | CoRE stack starter-kit to understand the data and run rapid analysis, API invocation | Video |
| Session 03 | Dec 12, 2025 | Technical details behind the CoRE stack, pan-India micro-watershed registry | Video |
| Session 04 | Dec 19, 2025 | Find intersecting, upstream, and downstream micro-watersheds, and build interactive maps. | Video |
| Session 05 | Jan 2, 2026 | Ideas proposed by the community, beyond ideas mentioned in the detailed challenge page: – INREM’s proposal on building water quality maps – Kaustubh’s (APU) proposal on dashboards to study the ecology of lakes – Madhura’s (WCT) proposal on mapping command areas of reservoirs | Video |
| Session 06 | Jan 9, 2026 | Mentorship of participants. Plus, more ideas proposed by the community: – Arghyam’s proposal on building a greywater management tool – Tracker for protected areas in collaboration with IITB and Kalpavriksh | Video |
| Session 07 | Jan 16, 2026 | Discussion on ongoing projects and contributions: – Forest structural analysis, by Dipak, to identify core, periphery, bridge, small tree patches, etc. – Adding eBird and iNat data on waterbody hotspots, by Anoop and Kaustubh, for lake ecology monitoring. – Scraping agri-census data, by Shivam, to download tehsil-wise data of crop production statistics. – Automated farm boundary delineation for farm-level resilience planning, by Pavan and Raman, using models created in Wang, et al. and integrated into CoRE stack pipelines after significant cleaning by identifying and rejecting scrub areas, farm ponds, etc [sample output]. | Video |
| Session 08a | Jan 23, 2026 | Discussion on ongoing projects and contributions: – Presentation by Sanket Gharat on building a dashboard for the Nashik district with time-series data on onion prices (from data.gov) put together with locations of mandis and traders (mapped manually) and layers from the CoRE stack including on cropping intensity from 2017 onward and waterbodies detected using remote sensing. Github repo. Tons of interesting observations and excellent prospects for econometric analysis on this data! – Progress by Anoop and Kaustubh on invoking iNat and eBird APIs to get data on bird sightings alongside lakes in Anekal. – Progress by Shivam on building a robust scraper of cropping data at the tehsil level. Lots of lessons to build such scrapers. | Video |
| Session 08b | Discussion with Tanveer on an interesting research problem to assess the impact of waterbody rejuvenation interventions. We have published dashboards on de-silting interventions in waterbodies across Maharashtra, Madhya Pradesh, and Uttar Pradesh, and the kind of change in surface water availability that resulted. ML and double ML techniques can be used to understand individual and average treatment effects of these interventions, and potentially even build into predictive models on what impact can be expected on a given waterbody based on whether it is on/off a drainage line, its catchment area, underlying aquifer, soil, cropping pattern, etc. | Video | |
| Session 09 | Jan 30, 2026 | Fantastic progress by Anoop on building a system to pull in citizen science observations on flora and fauna from the eBird and iNat APIs, in and around the waterbodies in Anekal. Background: Kaustubh has been working since several years on the Tanks of Anekal project to document the state of urban lakes in the Anekal taluka in Bangalore – land diversion, ecosystem functioning, biodiversity – and bring various stakeholders together for lake conservation. And in the Know Your Landscape dashboard on the CoRE stack we recently released a feature to track land-use changes inside and around waterbodies. Can’t wait to eventually integrate Anoop’s work into the CoRE stack waterbody dashboard so that biodiversity changes can be seen alongside land-use changes and climatic data. And hopefully this will inspire someone to also research on a comprehensive modeling of ecosystem functioning of lakes, understand how waterbody rejuvenation efforts might be altering this functioning, and build relevant decision-support systems for conservation of lakes. | Video |
| Session 10 | Feb 6, 2026 | Trishal has built Fields – an app that lets users define various geospatial layers of interest, makes the layers available offline, and lets people validate these layers. This is a super useful and important functionality because such datasets often need to be calibrated to more accurately match local observations and actual groundtruth data is needed for this purpose. Github repo. Report. The possibilities go much beyond. What if all this composite info from multiple layers is sent off to AI agents to consult research papers and come back with some sense making based on this? Or the converse for active learning, to point out spots that should be visited to confirm the observations because they seem weird? And what if this can become a new citizen science movement, for people to get outdoors and turn into detectives – go the spot marked X and see if you find a hidden pond, and where you’ll get a clue for the next treasure… | Video |
| Session 11 | Feb 11, 2026 | Ksheetiz presented explorations with pulling weather forecast data into the CoRE stack and making it available through APIs. We tried using the WeatherNext forecasts accessible via GEE and BigQuery, and NOAA’s forecasts accessible via Dynamical.org hosted on Source Cooperative. How do they compare with OpenMateo is a question we’ll explore soon. | Video |
| Session 12 | Feb 18, 2026 | Completion of the POC by Anoop on augmenting tanks in Anekal with biodiversity data! We are now discussing how to generalize this to integrate with the CoRE stack and with the Tank of Anekal website. | Video |
| Session 13 | Mar 13, 2026 | Several announcements! – We are thrilled to announce that FOSS United is giving a follow-up grant to CoRE stack innovation participants Anoop, Trishal, and Sanket to take their PoC submissions to full-fledged products and for integration into the CoRE stack. Read more here. – Following the Hackathon on Geospatial AI organized by Professor Anil Madhavapeddy as part of the AI Summit where Anil introduced the TESSERA remote sensing foundation model, the University of Cambridge is supporting student innovations to find novel uses for the TESSERA embeddings. Read more here. And try out the embeddings here. | |
Nov 22, 2025: We are super excited to launch the first edition of the CoRE stack innovation challenge on geospatial programming!
The CoRE stack is taking a novel approach to geospatial programming by providing ready-to-use pre-computed data of various landscape entities – micro-watersheds, waterbodies, forests, agroforestry plantations – organized in nested and connected spatial units, and populated with tons of datapoints about these entities to build a comprehensive place-based social-ecological understanding. Researchers and developers therefore do not need to worry about running complex geospatial workflows to generate all this data – we have done all that for you. You can rather just focus on asking the right questions from the data.
Check out the challenge details here.
The CoRE stack has been built in an extremely open and collaborative manner, and the challenge aims to do the same: Let us use this as an opportunity to not just come up with ideas, but also help point out bugs, solve these bugs, identify new APIs and datapoints that will help, and the engineering and maintainers team will do their best to do this quickly.
Who should participate
- Ecologists and hydrologists
- Researchers in water security and land use
- Geospatial engineers, data scientists, software developers
- NGOs, community technologists, and practitioners working with rural landscapes
- Students and open-source contributors interested in socio-ecological data
Challenge types
- Data Exploration & Insights: Use CoRE Stack layers to answer concrete landscape questions (comparative analyses, trend detection, counterfactuals). Deliver reproducible notebooks, maps, and concise interpretative notes for practitioners. Several such problems are outlined in the next section.
- Tooling, APIs & Developer Tools: Build developer-facing tools or libraries that make the CoRE Stack easier to use (client libraries, wrappers, STAC tools, boundary-clip and vectorization utilities, etc.).
- Data stories & UX Integrations: Create user-facing dashboards, chatbots, WhatsApp-shareable slide generators, or lightweight tools that practitioners and village communities can easily use to tell data-based stories. Focus on clarity, localization, and actionable outputs.
Timeline & milestones
- Launch: Nov 22, 2025
- Weekly developer community calls / mentorship: Fridays, 3-4pm
- Submission deadline:
Dec 31, 2025we have converted this to rolling contributions - Shortlist & demos:
Jan 15, 2026discussed in the weekly dev calls - Winners announced & prize distribution:
Jan 31, 2026converted to rolling contributions and evaluations
Prizes
- Cash prizes of the order of Rs 10,000 for exciting solutions plus merch from FOSS United for all participants.
- Additionally, mentorship sessions with domain experts in the CoRE stack network for top finalists.
- And opportunities to integrate winning work into the CoRE Stack ecosystem and technical support for adoption.
We also want to use this an opportunity to build an opensource community around the CoRE stack. Please join the Googlegroup and Discord channel, and participate in weekly community calls on Fridays 3-4pm IST.