All CoRE stack code, datasets, technical methodology documents, research papers, etc. are published in the open [github repo, deep-wiki documentation]. You can also contribute to the CoRE stack and help build out this community-based Digital Public Infrastructure for climate change adaptation for rural communities.
The CoRE stack can be logically divided into different layers, starting with a datasets layer at the bottom, on which analytics can be derived at different spatial and temporal units, and a layer of tools in which the datasets and analytics are used to inform community action.
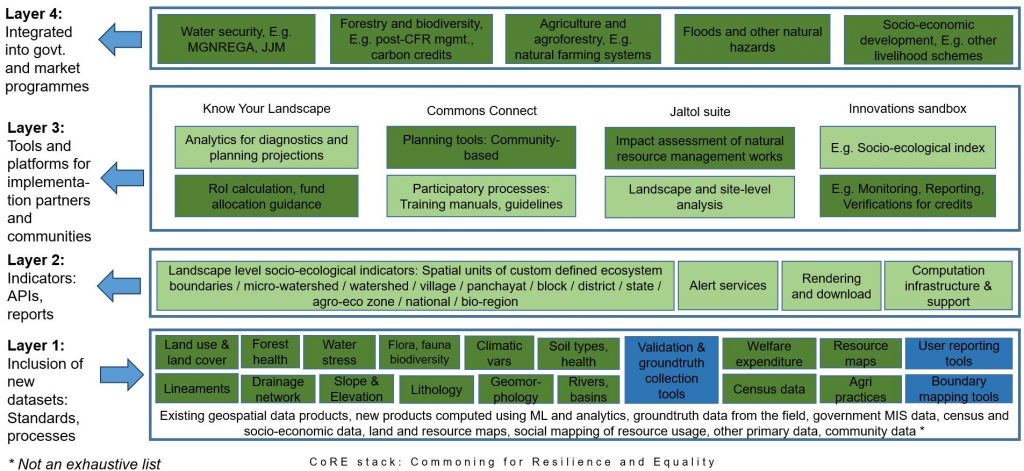
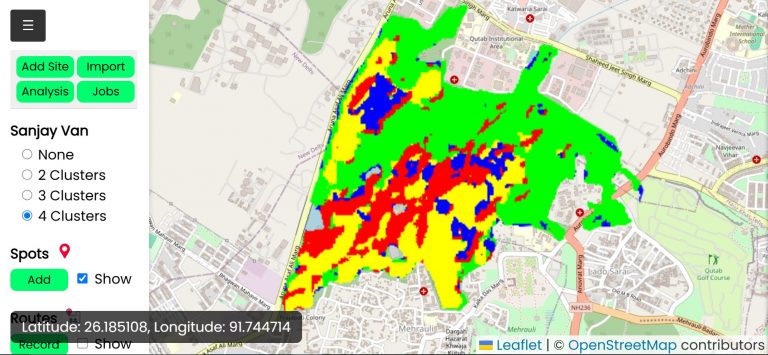
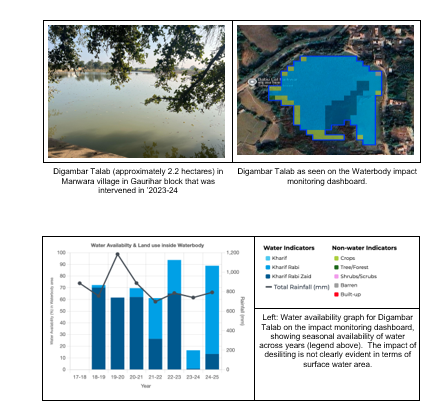
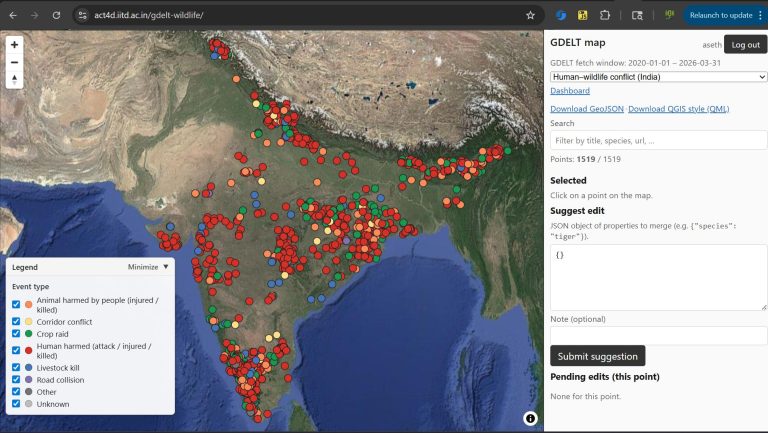
Most datasets and analytics are generated computationally using machine learning models that run on satellite data, or hydrology models that simulate historical rainfall, etc [technical manual]. The CoRE stack implements several dozen algorithmic pipelines for this purpose that can be executed for a given region of interest like a Tehsil or micro-watersheds, for a given range of time and also triggered automatically on a regular basis to keep the data up to date.
This detailed guide explains how you can contribute by writing new pipelines to generate and process new datasets. A long wishlist of datasets and indicators on which we are looking for support is available here. These indicators are a subset of the ones needed to build a comprehensive social-ecological understanding of a landscape.
Pre-computed data can subsequently be accessed through APIs. Read here for an outline of how to invoke these APIs from your own apps, chatbots, and other tools is also given. Before you use the APIs, it will help to get a sense of the overall CoRE stack data structure and how we represent landscapes as constituted of spatial entities that are related to one another through containment, connectivity, etc. links. Watch the call recordings from the weekly dev calls that happen on Fridays 3-4pm IST and join the Googlegroup and Discord channel.
Watch this video about the CoRE stack presented at India FOSS 2025.